

Connecting clinical decision- making and psychological research with rule-based methods
Psychologists working in practice have to make decisions about clients, with limited time and information. New data-analytic algorithms may provide empirical research results that are more efficient and easier to apply in psychological practice.
Making decisions in psychological practice
When we make decisions in the real world, we are faced with limitations to the information, cognitive resources, and time at our disposal. This is called 'bounded rationality', and as psychologists, we have to find a way to deal with those limitations when we make decisions about clients or patients. At the same time, professional standards require psychologists to take an evidence-based approach: the accuracy of assessments and efficacy of treatments provided should be supported by empirical research. Perhaps even more importantly, reviews and meta-analyses on the accuracy of clinical judgment ('clinical prediction') and empirically derived formulas ('statistical prediction') have shown the latter to be more accurate than the former. So ideally, for psychologists working in practice, empirical studies should supply them with statistical prediction rules that can be easily evaluated.
Popular statistical models in psychological research
However, in most empirical studies in psychology, data are analyzed using generalized linear models, or GLMs. With these models, we can predict the value of a variable by adding up the contributions of other predictor variables (often called 'risk' or 'protective' factors). GLMs are powerful models, as they are conceptually simple and have desirable properties in terms of stability and accuracy; this may explain their popularity among social scientists.
As an example of a GLM, let’s take an analysis performed in a paper by Penninx and colleagues, who studied factors that predict whether patients who currently have an anxiety or depressive disorder will still have such a disorder after two years. The researchers found seven variables or factors that predicted the presence of a disorder; these are shown in the table below.

This model offers us some important insights into risk and protective factors for developing a chronic depression or anxiety disorder. However, if we want to use the model to assess a new patient’s risk of developing a chronic disorder, we have to assess the value of all seven variables and calculate a weighted sum of their values. This may require too much time and resources, especially for a psychologist working in clinical practice, where both these commodities are scarce.
Fast and frugal decision-making
Researchers like Gigerenzer and Katsikopoulis have therefore suggested using so-called 'fast and frugal trees' for statistical prediction in clinical practice. A fast and frugal tree is a very simple decision tree, consisting of only one branch. At every level of the tree, the value of only one variable is assessed; on the basis of that value, either the tree is exited and a final decision made, or the value of the next variable in the tree is assessed. An example of such a tree is shown below. It can be used by doctors for deciding whether to prescribe the antibiotic macrolides to children with an infection.
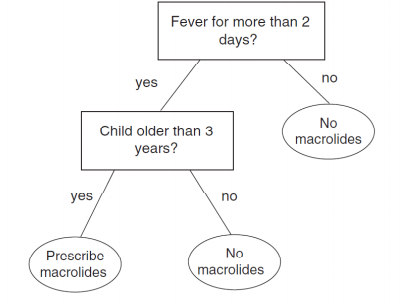
These fast and frugal trees seem very helpful for performing statistical predictions when time, information, and resources are limited. However, the trees have to be derived in such a way that they provide accurate decisions, and that the variables are assessed in the most efficient way.
New tools for prediction
This is where rule-based methods may come in handy. Rule-based methods are a relatively new data-analytic tool developed in the field of statistics and data mining. Friedman and Popescu have developed one of the most promising rule-based methods: the RuleFit algorithm. This algorithm derives a so-called prediction rule ensemble, using exactly the same data as are used to fit GLMs. However, the prediction rules in the ensemble can be represented as fast and frugal trees, which may be easier to use in practice than GLMs.
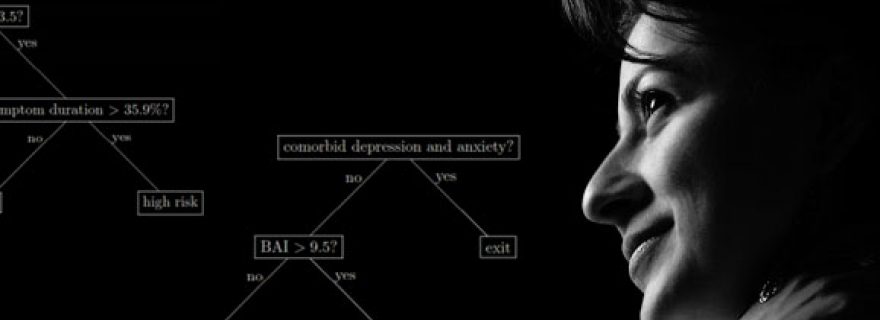
In a paper we published this year, we showed an example of a prediction rule ensemble for predicting the presence of a depressive or anxiety disorder, by applying the RuleFit algorithm to the same data as the original study by Penninx and colleagues. We found a prediction rule ensemble of two simple rules, providing decisions whose accuracy was comparable to that of the original GLM. Below, the two rules in the ensemble are depicted as fast and frugal trees. On average, evaluation of the rules in the ensemble required assessing the value of only three variables, whereas using the GLM for prediction would require assessing the value of seven variables in the table above.
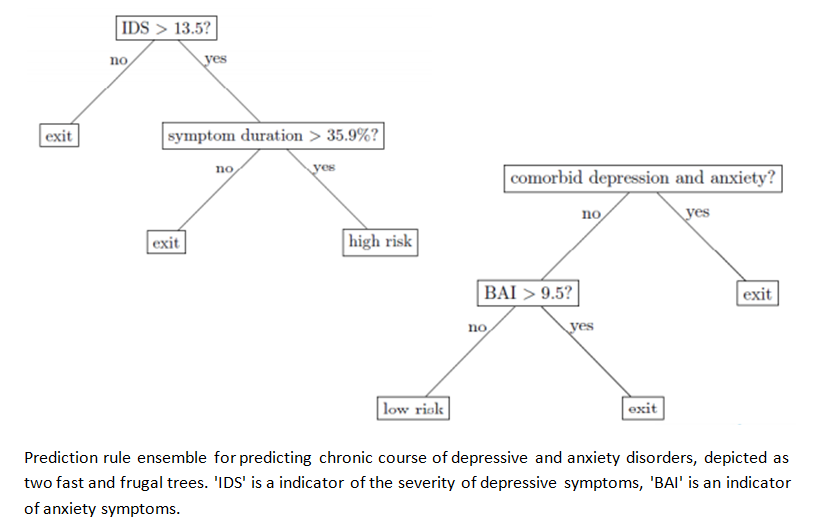
Therefore, we concluded that rule-based methods, and the RuleFit algorithm in particular, are promising methods for creating decision-making tools that are simple and easy to use in psychological practice. In future research, we will work on further improving the applicability, accuracy, and ease of use of rule-based methods.


